
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 11번가 모바일
- 11번가 모바일 매크로
- 11번가 매크로 소스코드
- 리더스 매크로
- 매크로
- 리더스시스템즈
- 웹
- react
- 11번가
- Android
- 11번가 매크로
- 3070ti
- 3080
- 앱
- 안드로이드
- 설치
- java
- 3080fe
- 애플리케이션
- Javascript
- 그래픽카드 매크로
- 리더스시스템스 매크로
- 머신러닝 #인공지능 #딥러닝 #객체인식 #알고리즘
- 프로그래밍
- 리더스시스템즈 매크로
- 안드로이드 스튜디오
- 개발
- 11번가 매크로 만들기
- 11번가 매크로 파이썬
- 자바
- Today
- Total
Honest Coder
머신러닝 선형 회귀에 대해서 알아보자! 본문
앞편에 머신러닝에 대해서 짧게 알아보았습니다.
머신러닝은 "학습하는 방법"에 따라 지도 학습, 비지도 학습, 강화학습 세가지로 분류할 수 있었는데, 이번에는 머신러닝의 대표적인 알고리즘중, 한가지인 선형 회귀 알고리즘에 대해서 알아보겠습니다.
선형 회귀는 입력값의 특징들을 사용해 값을 예측하는 알고리즘입니다.
선형 회귀 분석의 목표는 함수가 입력 데이터 세트에서 가장 비슷한 결과값을 찾을 때까지 비용 함수를 최소한으로 줄이는 것입니다.
여기서 비용함수는 "해답에서 얼마나 떨어져 있는지를 보여주는 오차 함수"입니다.
간단한 예제를 예로 들도록하겠습니다.
ex 1)
25년 전에 만들어졌고, 100스퀘어의 방이 3개 있는 2층 건물을 소유하고 있다고 가정한다. 그리고 도시를 열개 부분으로 나눠 각각 1에서 10까지 숫자로 표현한다고 가정했을때 위 집은 7인 장소에 위치해 있습니다.
이렇게...
5차원 벡터 x = (100, 25, 3, 2, 7)로 피라미터화 할 수 있습니다.
이 집이 100,000만원 이라고 가정한다면, 함수 f(x) = 100,000라고 표현 할 수 있습니다.
우리가 해야 될 것은 f를 만드는 것 입니다.
선형 회귀 로직에서...
100*w1 + 25*w2 + 3*w3 + 2*w4 + 7*w5 = 100,000을 만족하는 벡터 w = (w1, w2, w3, w4, w5)를 찾는 것입니다.
만약 이러한 집이 1,000개가 있다면, 모든 집에 대해 일련의 가정들을 반복할 수 있고, 이상적으로 모든 집에 대한 정확한 값인 벡터 w를 예측할 수 있습니다.
처음에 하나의 무작위 값인 w값을 선택했다고 가정하면, 이경우에는 f(x) = 100*w1 + 25*w2 + 3*w3 + 2*w4 + 7*w5이 100,000 되는것을 기대하지 않을 수 있습니다. 그래서 다음과 같은 오차를 계산할 수 있습니다.

이건 하나의 x의 제곱 오차일 뿐이고, 모든 예시에 대한 제곱 오차의 평균은 만든 함수와 얼마나 다른지 의미하는 비용이 됩니다. 이것을 구하는 목표는 오차를 최소화하기 위함이고, w를 반영해 비용 함수의
미분값 δ
을 계산하는 것입니다.
미분값은 함수가 증가하거나 감소할 때 방향을 제시해 주기 때문에 w를 반대 방향으로 옮기면 함수의 정확도가 향상 됩니다.
이것이 선형 회귀의 핵심입니다.
비용 함수의 최솟값으로 옮기면 그 값이 오차가 됩니다. 물론 미분의 방향에 따라 얼마나 빨리 움직이는지 결정되지만 미분의 값은 방향만 결정합니다.
비용 함수는 선형이 아니므로 미분값의 방향이 제시하는 작은 단계들만 수행하는 것이 중요합니다. 단계가 너무 크면 최솟값에서 너무 많이 벗어나기 때문에 수렴을 할 수 없게 됩니다. 단계들의 규모들은 학습률이라 부르고, 이 규모들은 기호 'lr'을 사용해 표현합니다.
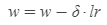
로 정의하고 나면, 더 나은 해답을 찾기 위해 선택한 w로 상향시킵니다. 이 과정을 계속 반복하면 함수 f에서의 최선의 선택값인 w를 만들게 됩니다. 그러나 이는 특정 장소에서만 발생하는 과정이고, 만약 공간이 블록하지 않으면 전체에서 가장 좋은 값을 찾을 수 없다는 것이 중요한 사실입니다.
알고리즘은 극소점이 여러개 일경우 극소점 중 하나에 멈춰 꼼짝하지 못할 것이고, 빠져나오기 힘들어 오차 함수의 최소값에 도달하지 못할 것입니다.
'머신러닝' 카테고리의 다른 글
| 인공지능 맛보기 1탄, 컴퓨터 비전 (2) | 2022.04.18 |
|---|
